During one of my first few weeks at work, I remember talking to a senior engineer about the surging hype around AI products. I brought the derisive outlook characteristic of inexperience, brushing the concerted efforts of some very smart engineers and entrepreneurs away with "they're just making OpenAI API calls". I have since developed a dislike for people who speak with the self-assurance of my old self from a few months ago, and I've aligned myself more closely with this post I saw on TikTok.

The engineer explained in a not so unserious tone that the term "wrapper" had dubious utility in the software engineering domain. Any metal shell be could fashioned to house a supercar engine, but that shell does not assume supercar status so easily. That engine would have to be placed in an equally imposing body, and only out of the harmony of their strengths, would a supercar be born. To bring about such a union, you would need equally competent builders, a defiant vision, and so on. The LLM APIs then can only be said to be the engine. What we do with it is a whole different engineering pursuit.
A few weeks after this conversation, we were handed an engine, the Vertex AI API, and tasked with building an AI agent for internal use at my company. I had little knowledge for defining an agent, let alone building one. My first spike landed me on this article from Anthropic, which, foundationally, defined "agent" for me. It drew the important distinction between workflows and agents, and I quote, "agents [...] are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks". I had grown fond of Sonnet 3.5, so I trusted its creators to guide me through this terrain.
The next few spikes got me through the elementary knowledge needed to start building, although that wouldn't start until a month later. I had a good deal of context already from a few relevant classes I had taken in university (I had just taken Applied Machine Learning in my final semester), so none of this was exactly new to me, but my course content was too low level to be of much help for the task I had at hand. I wasn't being asked to build a convolutional neural network from scratch anymore, but rather being asked to solve a business problem. So, I got myself up to speed with the basics of chunking text, working with emebeddings and vector databases, LLM function calling — the engine had been taken care of; I was preparing to build a worthy shell.
We looked into a few different agent building frameworks that are already quite popular in this space, including LangGraph, but also CrewAI, Flow, and, Agno, to name a few others. They promised to to be abstracting away some major heavy-lifting involved in building an agent, but on the other hand, each of them seemed to be imposing their own philosophies of agent building. In the minimum, CrewAI required us to name our modules in accordance with their naming convention, while frameworks like Controlflow did not natively support parallel agent calls. Not that nothing in the likes of the internal tool we're building had been done before, but we had certain constraints that required us to jump through extra hoops were we to implement it with the help of a framework.
Eventually, we realized that frameworks offered us little value. We still had to define the functions (LLM's tools) ourselves, and an off-the-shelf framework would only be wrapping our code, while largely closing off customization options. At this stage, we decided to build our own agentic framework, one that would be modular and extensible by default, and allow future developers to easily add more agents as they wished. We built a few necessary autonomous agents necessitated by our functional requirements, but the way that our system has evolved, adding another tool to our system involves only three steps: creating your tool module, writing prompts, and placing it in a folder in the repository where our custom orchestrator can access them.
Framework
We built an AI agent that sits in the Zendesk ticket sidebar and has access to the support ticket that a customer support agent is viewing. Internally, it can access enterprise knowledge necessary to help customer support answer customers' queries more efficiently and cut down much of the research work involved in resolving a ticket. To achieve this functionality with our custom framework, we came up with our own nomenclature, and in the following sections, I'll describe a few basic concepts.
Orchestrator
The Orchestrator is the central component of our system that presides over the
agentic architecture. It is responsible for receiving user queries, invoking
appropriate agents when necessary, and returning the final, synthesized response
to the user. Although it is stateless in an architectural sense, it maintains
state for the entire duration of a chat thread between a user and the system in
the context of a single ticket with the help of a cache layer backed by Redis.
The Orchestrator can, and is encouraged to, respond directly to the user like
a regular AI chat application wherever appropriate. However, if external
information is required to satisfy the user's need, it uses a Router to
determine which agents to invoke based on the user's query, ticket context, and
conversation history, and it invokes the agents in parallel, allowing for faster
response times and more efficient processing of user queries. It generates
tailored "enhanced queries" for each agent that it invokes – a plain-text
versions of the user's query augmented with further context – to send to the
selected agents.
Each chat session has its own Orchestrator instance, which helps demarcate
concurrent chat sessions. When a connection is first established, the backend's
entry point sets up a chat session and hands it off to the Orchestrator to
handle subsequent requests.
Agent
An agent, inheriting the BaseAgent class, is a semi-autonomous retrieval
module that is capable of generating results based on plain text queries sent to
it. They are functionally stateless, inasmuch they do not persist any context
between requests, which makes it much easier to scale each agent independently.
Since agents are independent, some evolved to be more complex than others,
depending on the data they work with.
From a high level, each agent is assigned a few tools that they can leverage to interact with external services. When they receive a query, they autonomously nominate a tool, generate arguments for the selected tool, execute the retrieval task, validate the results, and then return a synthesized response to the orchestrator. The agents also optionally accept a SocketIO session – while they're doing all the work, they'll send "thinking" messages to the chat interface to keep the user updated!
Vertex AI Interface
VertexAI is at the core of our agent, and we made use of several APIs from
VertexAI's Python SDK to generate responses with the gemini-2.0-flash-001
model, going so far as making our own module wrapping the VertexAI SDK to
streamline the code for interacting with LLMs. It mimics VertexAI's methods,
which helps avoid confusion when referring to the VertexAI documentation and
helped us cut down on the amount of boilerplate code we had to write for each
LLM call, such as converting the response to a Python dictionary or streaming
the response to the frontend.
We heavily leveraged the controlled generation API to get structured responses from the LLM. As an agent progresses through its workflow, at each juncture, it needs to make a decision and generate input for the next step. Instead of making two seperate calls to the LLM and incurring the latency of two calls, we can define a JSON schema that captures two related outputs, and then easily convert the LLM's response to a Python dictionary.
For example, when the orchestrator receives a message from the user, it can choose to either respond directly, or invoke retrieval agents to help ground its response in relevant information. Instead of making one call to make a decision, a second to generate a routing pathway or a direct response, and possibly a third to generate a query for a retrieval agent, we can condense all of this into a single call to the LLM. The LLM will then generate either a direct response, or a routing pathway with queries for the appropriate retrieval agents.
Howver, this streamlining had to be managed with great care. Bundling overly complex tasks with lower termperature outputs together in one LLM conversation turn yields poor results. With increasing cognitive load, LLMs tends to lose recall, and attempting to correct that with few-shot examples can backfire, leading to a Catch-22 of sorts. Too few examples, and the LLM will easily overlook them in a dense, context laden instruction block. Too many, and the LLM will start to overfit. I experienced a case where the orchestrator kept asking the agents about server scaling, even when nothing in the Zendesk ticket's context even remotely pointed to servers, because I had made the mistake of modelling all the examples after a dummy ticket on a scheduled server scale out request.
Redis for Managing Sessions
Using WebSockets for connecting to the client, while flexible and easy to set up, came with a few pitfalls. We used to hold chat sessions in memory on our Cloud Run service. Since Cloud Run is serverless, any time the instance exited, or restarted, all users would lose their active chat threads, with no ability to resume the chat after reconnecting to a new instance. But the server didn't even have to turn off for the client to be disconnected. When a user switched tabs, and our application's tab became inactive for a few minutes too long, the browser would automatically pause network activity on that tab. For us, this meant that if users were having a conversation with our agent, and then left to go check out something else in a different tab, they'd come back to our agent showing a "Disconnected" message in the chat interface. On top of this, Cloud Run imposes a one hour request timeout limit, which meant that each WebSocket connection could only live for an hour at maximum. To get around just the timeout issue, we had implemented a complicated mechanism to debounce socket disconnection events. We'd hold on to each user's session for 20 seconds after they disconnected, and if they reconnected within that time span, we'd resume their chat. However, if they did not, we'd proceed to cleaning up their session data. Still, a Cloud Run imposed constraint remained: there was no way of ensuring that clients always connected to the same server instance. Since Cloud Run automatically handles load balancing, it could very well reconnect to a different instance, which would cause a failure. Cloud Run does offer session affinity (sticky sessions), but this is best effort, and does not guarantee that the same user will always be connected to the same instance.
As it is probably becoming evident, this was not an entirely reliable process, and the overall system of managing sessions was flaky and not production grade.
Enter Redis, the one architectural component that fixed all of these problems in
one fell swoop. First, we integrated Redis into our SocketIO server, using it as
a SocketIO adapter. This meant that all socket traffic now moves through Redis,
and we can let Cloud Run handle scaling on its own. Second, since we moved all
the state out of our server, even if our server scales down to zero instances,
it does not impact the user at all. Session data, including but not limited to
thread history (the chat thread that the user sees in the interface) and the
model history (the communication between our system and the driver LLM), is
stored in Redis as soon as these are updated during a chat, and loaded back into
an Orchestrator instance to utilize when a new chat message comes in. If a
client disconnects, a TTL of 2 hours is set for their particular chat thread, and
their data is backed up in to Spanner. If the client reconnects within 2 hours,
the TTL is simply cleared. If not, Redis cleans up the stale session
automatically. In the case that a client reconnects after 2 hours (imagine they
were on a different tab for longer than the TTL duration), Redis is easily
hydrated with their session data from Spanner, and we're able to resume the same
chat session for the user.
Now, our application withstands just about everything: timeouts, inactivity, and even server crashes.
A Word on Google Cloud Spanner
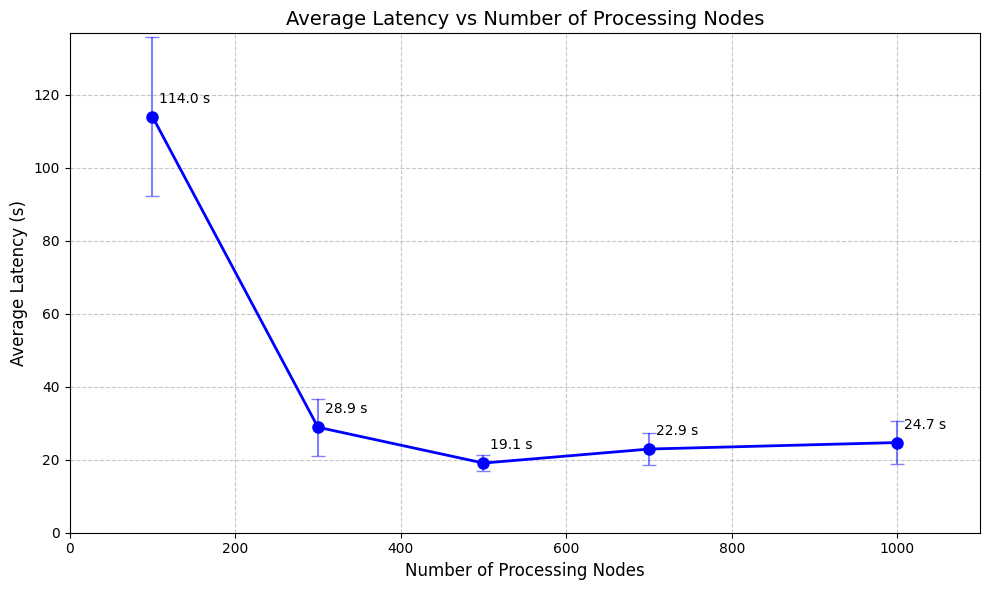
We did rounds around CloudSQL, Pinecone, Weaviate, and a few other databases popular in AI applications. Eventually, we landed on Google Cloud Spanner. Although Spanner is much more powerful than what our app currently leverages, it also shines in several other areas where other vector databases fell short. For example, Spanner let us store vector embeddings and tokens in one table, and we could perform hybrid searches and perform reciprocal rank fusion (RRF) on Spanner using a single query. We ran several tests on our data, and performance gains after 400 processing units seemed to level off, which meant that we would not have to scale beyond 0.4 Spanner nodes, create as many separate databases as we wanted, and only pay for compute and storage.
It might be interesting to note that, on a lower level note, creating
connections to Spanner is expensive, and google-cloud-spanner is already
designed to handle connection pooling. Our SpannerConnectionHandler class
implements the singleton factory pattern that keeps a single connection to a
Spanner instance alive for the entire lifetime of the application while
maintaining a dictionary of references to the separate databases in the Spanner
instance. For example, you can "ask" for a reference to the cache database by
writing SpannerConnectionHandler("cache").get_database().
A Word From Barthes
In an internal document, I wrote the following, and it seems fitting to quote it here to end this already long post.
Homaging the Citroën DS, the French essayist Roland Barthes wrote, "I think that cars today are almost the exact equivalent of the great Gothic cathedrals: I mean the supreme creation of an era, conceived with passion by unknown artists, and consumed in image if not in usage by a whole population which appropriates them as a purely magical object" (Barthes). It would be a fair estimation to say that had Barthes experienced artificially intelligent multi-agent systems, he would have dignified the technology with a similar, if not more profound, sentiment.